ThreadLocal的使用与源码
使用
当有一个单例类中有实例变量,而业务逻辑又要对变量进行处理,当有多个线程同时操作时,如果没有给处理代码加上锁,就有可能出现线程安全问题。如:我们最常见的获取JDBC连接的
连接,还有我们交给Spring容器管理的类等
1 | public static void main(String[] args) throws InterruptedException { |
输出结果为:
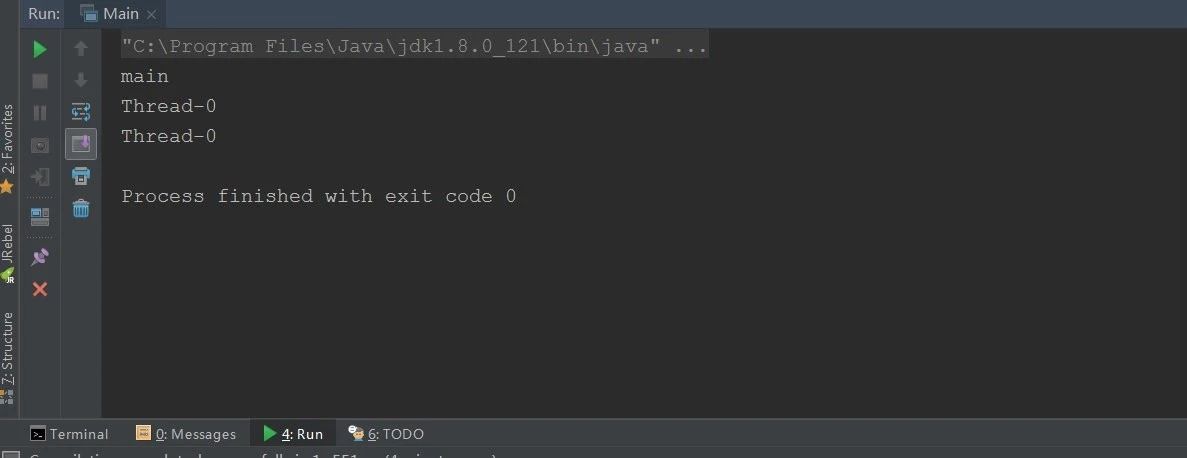
在上面的Test单例的,就如我们交给Spring管理的Bean, 当有两个线程同时操作时,其中一个先操作修改了,刚好另一个线程拿到cpu时间片,就会引发线程安全问题。
所以我们可能需要在修改数据的地方加上同步锁,但这样性能又不好。这时就可以使用ThreadLocal了。
1 | public class Test { |
再运行:

发现两个线程已经互不影响了,即使线程a设置了自己线程名,b线程输出的还是b线程名。
源码
主要是三个方法:
public T get();
public void set(T value);
public void remove();
get
public T get() {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程的ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null) {
// 通过ThreadLocal key获取Entry节点,并返回值
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result;
}
}
// 初始化值
return setInitialValue();
}
set方法
public void set(T value) {
// 获取当前线程
Thread t = Thread.currentThread();
// 获取当前线程的ThreadLocalMap
ThreadLocalMap map = getMap(t);
if (map != null)
// 插入Entry key为ThreadLocal,value为value
map.set(this, value);
else
// 新建一个ThreadLocalMap 并把第一个Entry插入
createMap(t, value);
}
remove
public void remove() {
// 获取当前线程ThreadLocalMap
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null)
m.remove(this);
}
详解
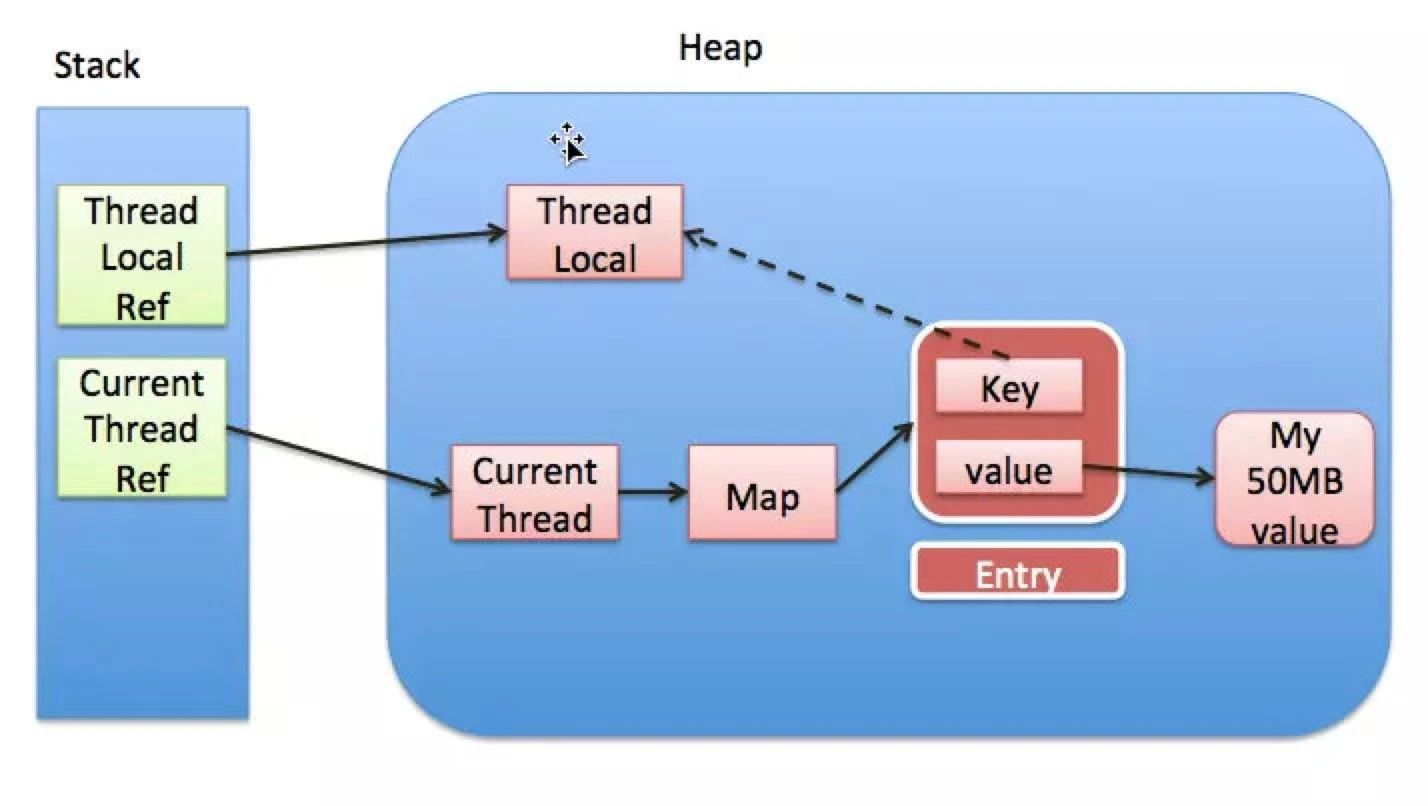
结构如上图所示
ThreadLocalMap是ThreadLocal的一个静态内部类,内部又有一个Entry的静态内部类,和有一个Entry数组用于存储<key, value>,key就是ThreadLocal,value就是要存储的值。
static class Entry extends WeakReference<ThreadLocal<?>> {
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
// 长度必须是2的幂次方
/**
* The table, resized as necessary.
* table.length MUST always be a power of two.
*/
private Entry[] table;
Entry继承自WeakReference并调用WeakReference构造函数,所以Entry的key是一个弱引用,即ThreadLocal是弱引用。
所以当外部没有引用到ThreadLocal时,那么系统GC时,经过可达性分析,GC Roots与ThreadLocal之间引用不可达,
ThreadLocal就将被回收。这样就出现了Entry中null key的情况,则无法访问到这些null key的值。如果这时线程结束,或者
段开值的强引用链(Thread ref -> Current Thread -> ThreadLocalMap -> Entry -> value),将Entry.value = null,则Entry能顺利被回收。
否则就会出现内存泄漏的情况。
但是,在我们现实开发中通常会用线程池来维护线程,即线程工作完后会放回到线程池中,所以就有可能出现内存泄漏的情况。
在源码中,作者也对这个问题进行了进理。见下
set操作
private void set(ThreadLocal<?> key, Object value) {
// We don't use a fast path as with get() because it is at
// least as common to use set() to create new entries as
// it is to replace existing ones, in which case, a fast
// path would fail more often than not.
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
// 采用开放地址法,hash冲突的时候使用线性探测
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
ThreadLocal<?> k = e.get();
// key相等直接替换值
if (k == key) {
e.value = value;
return;
}
// key为空 则调用replaceStaleEntry进行替换成新的值
if (k == null) {
replaceStaleEntry(key, value, i);
return;
}
}
tab[i] = new Entry(key, value);
int sz = ++size;
// 再次循环扫描清除null key的值,或者大小大于阈值扩容
if (!cleanSomeSlots(i, sz) && sz >= threshold)
rehash();
}
ThreadLocalMap并不是像HashMap那样当hash冲突时,用分离链表法来解决。它是用开放定址法,继续获取下一位置判断,直到该位置没有Entry节点。
在检测插入的时候,如果key相同,即相同ThreadLocal,则替换原来的值。如果key为空即脏Entry(Stale Entry)则调用 replaceStaleEntry 去处理。
tab[i] == null 则此位置为空,插入新的Entry,插入后会调用cleanSomeSlots去清除Stale Entry并判断扩容。
cleanSomeSlots
private boolean cleanSomeSlots(int i, int n) {
boolean removed = false;
Entry[] tab = table;
int len = tab.length;
do {
i = nextIndex(i, len);
Entry e = tab[i];
if (e != null && e.get() == null) {
n = len;
removed = true;
// 将i的值设为null 并将tab[i] = null 然后就继续向后检查,直至tab[i] == null 并返回i
i = expungeStaleEntry(i);
}
} while ( (n >>>= 1) != 0);
return removed;
}
参数:i 即刚刚插入新节点的位置,所以tab[i]不可能为null,直接从下一索引开始判断。
参数:n 是用来控制循环次数的,入参的时候它是map的实际大小(存放多少个ThreadLocal),如果没有遇到脏entry就整个扫描过程持续log2(n)次,log2(n)的得来是因为n >>>= 1,每次n右移一位相当于n除以2。
如果遇到脏entry,就返回tab[i] == null 的i,让下一次查找的起点为i,并且 n=len 即整个hash表的长度,扩大范围在进行扫描log2(n)趟。n的实际作用是扩大搜索范围。
注:在replaceStaleEntry方法中n的参数直接就是hash表的长度。
expungeStaleEntry
private int expungeStaleEntry(int staleSlot) {
Entry[] tab = table;
int len = tab.length;
// 将当前位置Entry清除
// expunge entry at staleSlot
tab[staleSlot].value = null;
tab[staleSlot] = null;
size--;
// 继续向后查找,如果key = null 也清除掉,直至tab[i] == null
// Rehash until we encounter null
Entry e;
int i;
for (i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
if (k == null) {
e.value = null;
tab[i] = null;
size--;
} else {
int h = k.threadLocalHashCode & (len - 1);
if (h != i) {
tab[i] = null;
// Unlike Knuth 6.4 Algorithm R, we must scan until
// null because multiple entries could have been stale.
while (tab[h] != null)
h = nextIndex(h, len);
tab[h] = e;
}
}
}
return i;
}
cleanSomeSlot总结
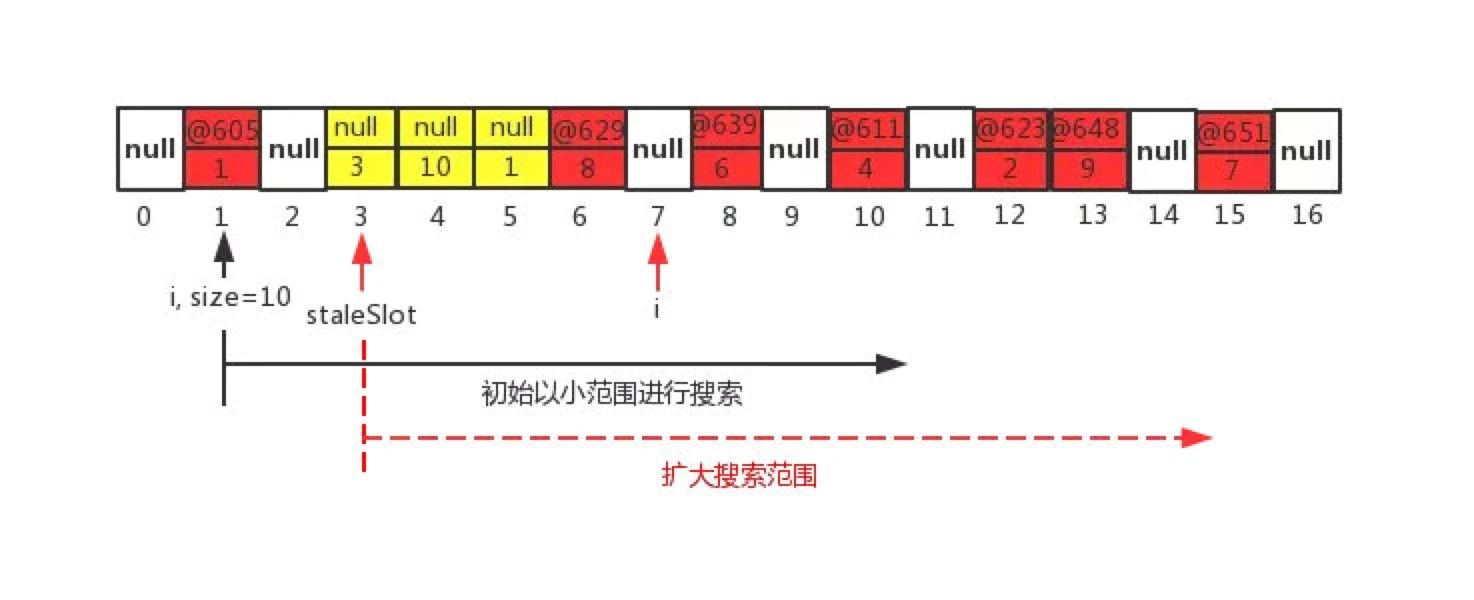
当前n等于hash表的size即n=10,i=1,在第一趟搜索过程中通过nextIndex,i指向了索引为2的位置,
此时table[2]为null,说明第一趟未发现脏entry,则第一趟结束进行第二趟的搜索。第二趟首先通过nextIndex方法,索引由2的位置变成了i=3,当前table[3] != null,但是该key为null,说明找到了一个脏Entry,
先将n置为哈希表的长度len,然后继续调用expungeStaleEntry方法,该方法会将当前索引为3的脏entry给清除掉(令value为null,并且table[3]也为null),然后它会继续往后环形搜索,往后会发现索引为4,5的位置的entry同样为脏entry,索引为6的位置的entry不是脏entry保持不变,直至i = 7的时候此处table[7]位null,该方法就以i = 7返回由于在第二趟搜索中发现脏entry,n增大为数组的长度len,因此扩大搜索范围(增大循环次数)继续向后环形搜索;
直到在整个搜索范围里都未发现脏entry,cleanSomeSlot方法执行结束退出
replaceStaleEntry
private void replaceStaleEntry(ThreadLocal<?> key, Object value,
int staleSlot) {
Entry[] tab = table;
int len = tab.length;
Entry e;
// Back up to check for prior stale entry in current run.
// We clean out whole runs at a time to avoid continual
// incremental rehashing due to garbage collector freeing
// up refs in bunches (i.e., whenever the collector runs).
// staleSlot为null key索引
// 向前搜索 起点为staleSlot,如果发现有脏entry,则更新slotToExpunge为null key的索引
int slotToExpunge = staleSlot;
for (int i = prevIndex(staleSlot, len);
(e = tab[i]) != null;
i = prevIndex(i, len))
if (e.get() == null)
slotToExpunge = i;
// Find either the key or trailing null slot of run, whichever
// occurs first
// 向后搜索 起点为当前staleSlot
for (int i = nextIndex(staleSlot, len);
(e = tab[i]) != null;
i = nextIndex(i, len)) {
ThreadLocal<?> k = e.get();
// If we find key, then we need to swap it
// with the stale entry to maintain hash table order.
// The newly stale slot, or any other stale slot
// encountered above it, can then be sent to expungeStaleEntry
// to remove or rehash all of the other entries in run.
// 如果key相同,则替换值并把位置交换到staleSlot的位置
if (k == key) {
e.value = value;
tab[i] = tab[staleSlot];
tab[staleSlot] = e;
// 相等说明向前没找到null key的entry,从起点i开始搜索,清除,这时i的被交换过去的脏entry
// Start expunge at preceding stale entry if it exists
if (slotToExpunge == staleSlot)
slotToExpunge = i;
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
return;
}
// If we didn't find stale entry on backward scan, the
// first stale entry seen while scanning for key is the
// first still present in the run.
if (k == null && slotToExpunge == staleSlot)
slotToExpunge = i;
}
// If key not found, put new entry in stale slot
tab[staleSlot].value = null;
tab[staleSlot] = new Entry(key, value);
// If there are any other stale entries in run, expunge them
if (slotToExpunge != staleSlot)
cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
}
针对前后有无null key的entry分为四种情况
向前向后都有
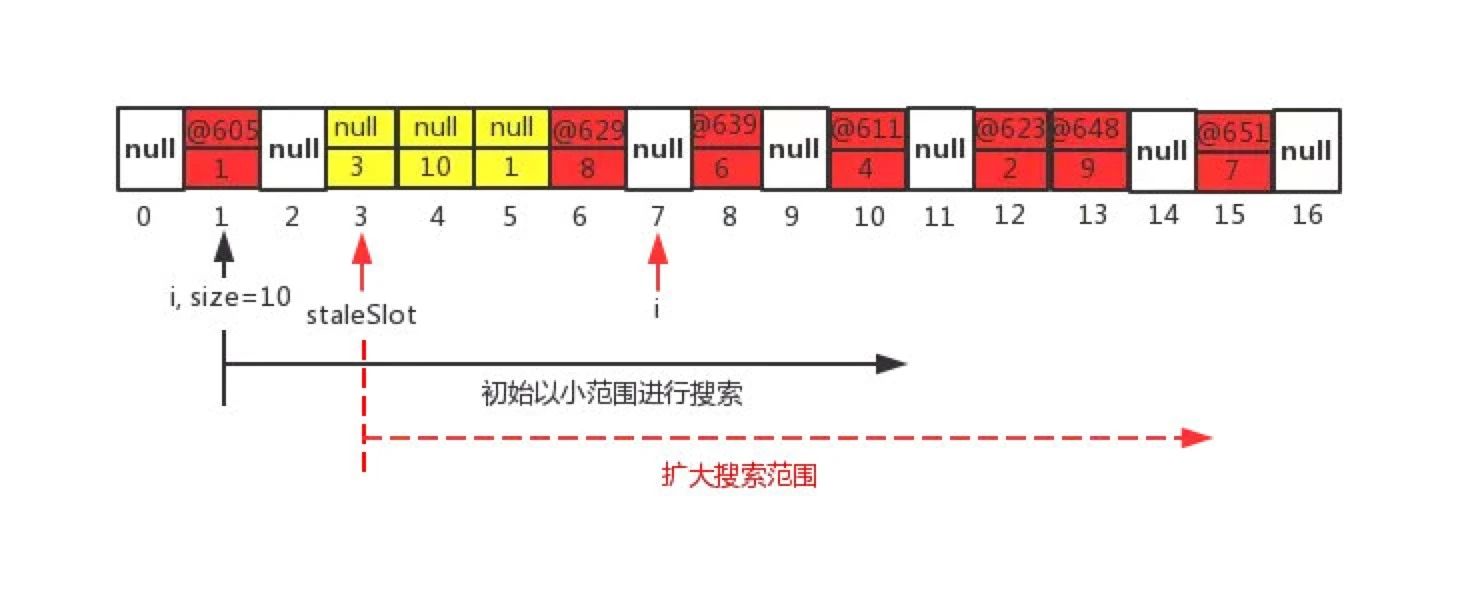
slotToExpunge初始状态和staleSlot相同,当前向环形搜索遇到脏entry时,在第1行代码中slotToExpunge会更新为当前脏entry的索引i,
直到遇到哈希桶(table[i])为null的时候,前向搜索过程结束。在接下来的for循环中进行后向环形查找,若查找到key相等的entry,
先覆盖当前位置的entry,然后再与staleSlot位置上的脏entry进行交换。交换之后脏entry就更换到了i处,
最后使用cleanSomeSlots方法从i(即slotToExpunge 向前搜索到脏entry的索引)为起点开始进行清理脏entry的过程
前有后没有
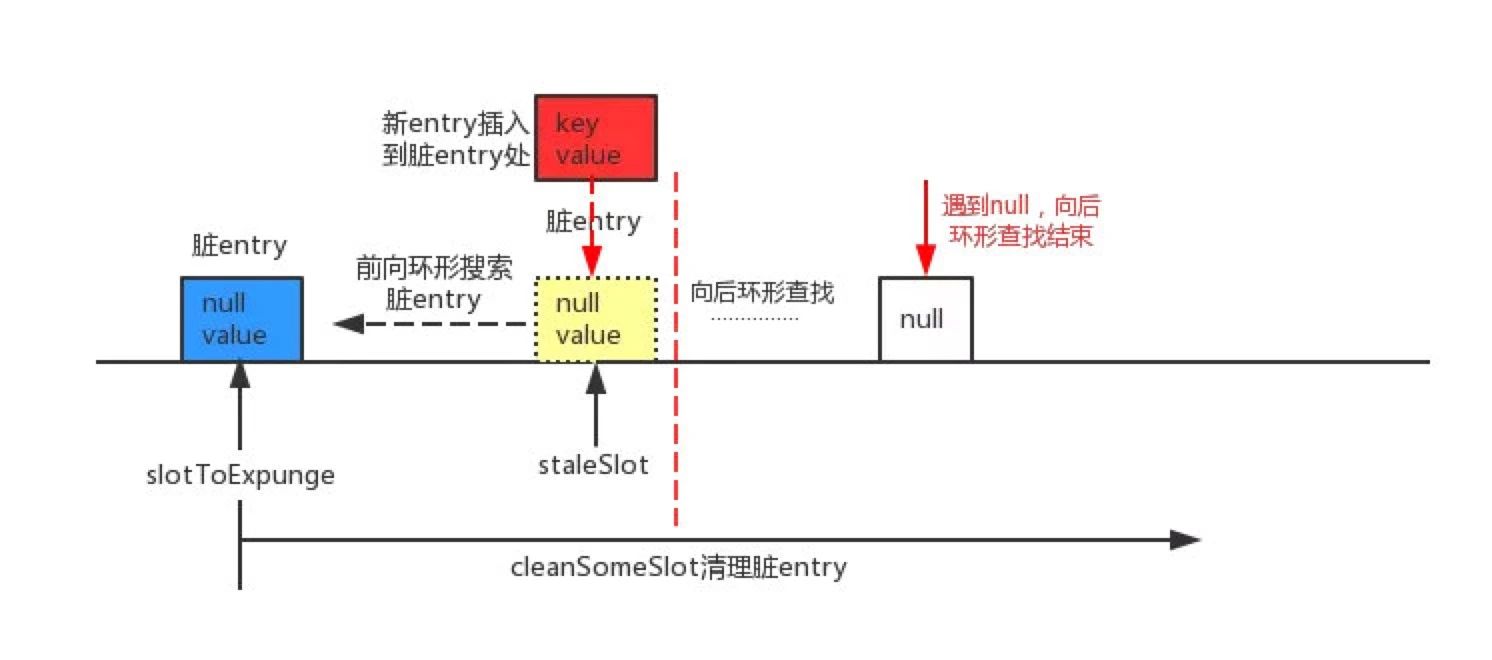
则把staleSlot上的entry清除,并把新的entry存入到tab[staleSlot]。然后调用cleanSomeSlots从slotToExpunge作为起点开始清除,
即向前搜索null key的索引。
前没有后有
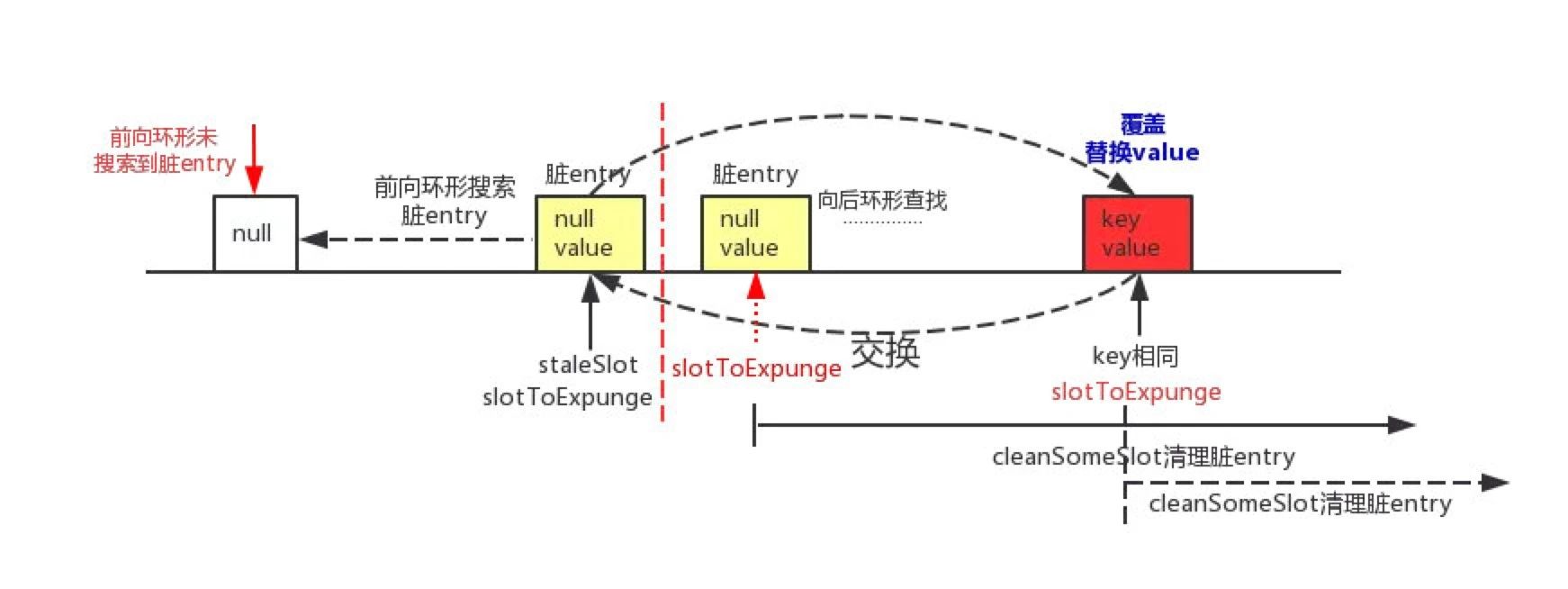
先覆盖当前位置的entry,然后再与staleSlot位置上的脏entry进行交换。交换之后脏entry就更换到了i处,
最后使用cleanSomeSlots方法从i为起点开始进行清理脏entry的过程
前后都没有
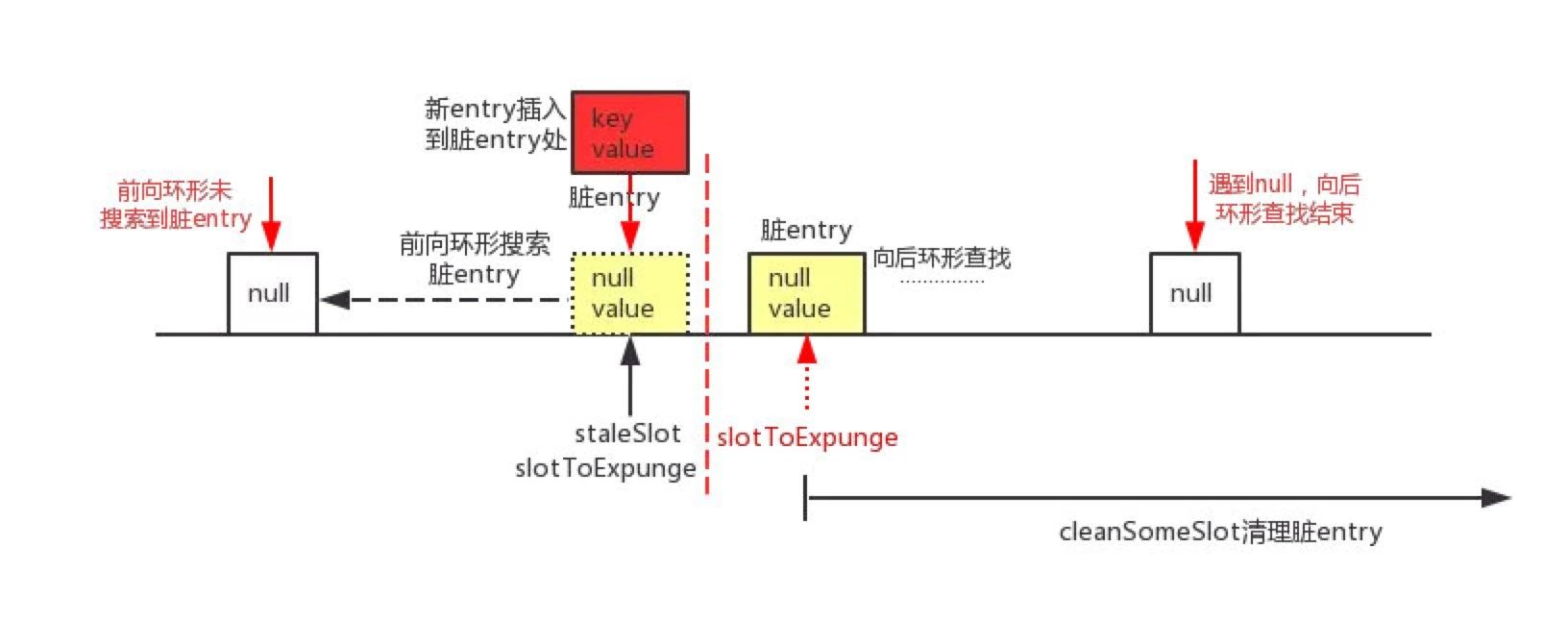
则把staleSlot上的entry清除,并把新的entry存入到tab[staleSlot]。然后也就不需要清除了
get操作
private T setInitialValue() {
T value = initialValue();
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null)
map.set(this, value);
else
createMap(t, value);
return value;
}
// 子类可以重写该方法,返回一个默认值
protected T initialValue() {
return null;
}
所以get方法就是 获取当前的线程 -> 获取当前线程ThreadLocalMap -> 获取储存这个ThreadLocal的Entry节点
-> 返回value值
如果value值为空或者ThreadLocalMap为空,则调用initialValue获取初始值,initialValue可以重写来返回一个默认的值,再把
ThreadLocal和null值存到ThreadLocalMap中。
remove操作
/**
* Remove the entry for key.
*/
private void remove(ThreadLocal<?> key) {
Entry[] tab = table;
int len = tab.length;
int i = key.threadLocalHashCode & (len-1);
for (Entry e = tab[i];
e != null;
e = tab[i = nextIndex(i, len)]) {
if (e.get() == key) {
e.clear();
expungeStaleEntry(i);
return;
}
}
}
删除则是搜索相同key的entry并调用expungeStaleEntry清除。
所以源码中通过expungeStaleEntry,cleanSomeSlots,replaceStaleEntry这几个方法来清理null key的enrty
弱引用导致内存泄漏问题
待续。。。