mybatis3 二级缓存
二级缓存的机制与工作模式
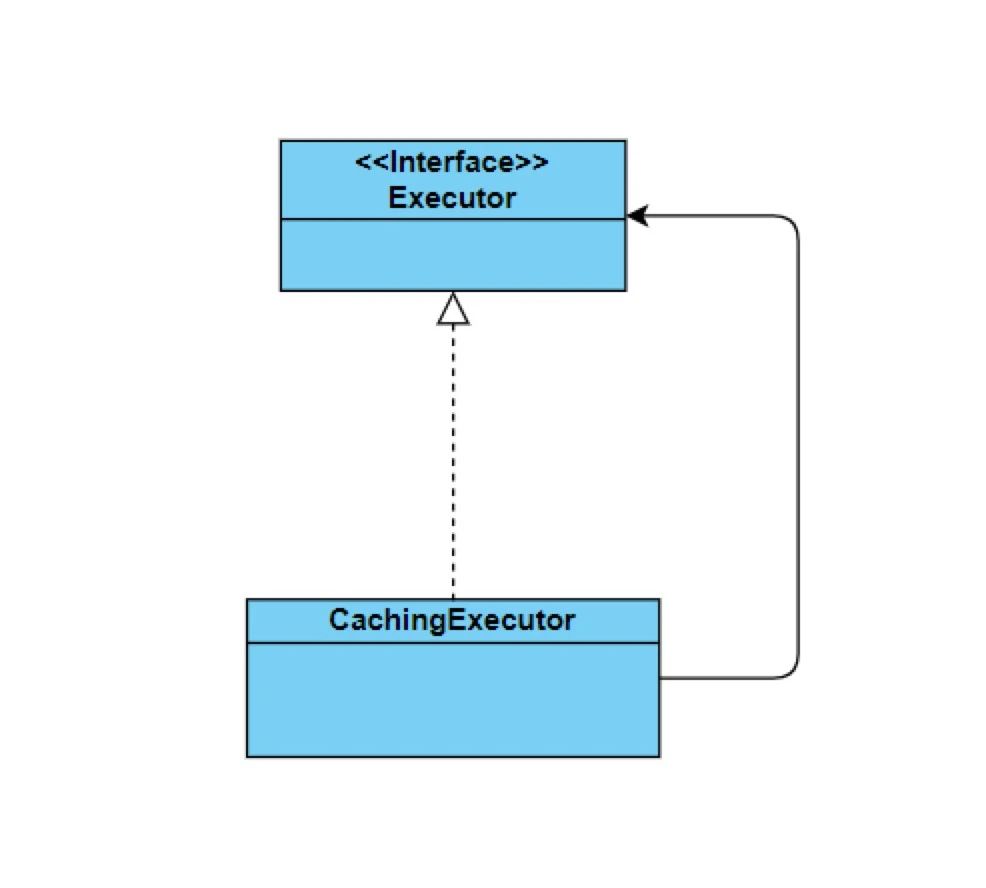
在上一篇 mybatis3 一级缓存 中提到一级缓存的最大共享范围是 SqlSession ,如果需要多个 SqlSession 共享,就需要使用二级缓存。二级缓存是默认开启的,当开启后( cacheEnabled=true )会使用 CachingExecutor 装饰 Executor 。CachingExecutor 是 Executor 的装饰者,以增强Executor的功能,使其具有缓存查询的功能。
类图如下:
以下是Configuration类初始化 Executor 对象代码片段:
1 | ........... |
注:本文参照3.5.5-SNAPSHOT版本,cacheEnabled 属性是默认开启的,在 XMLConfigBuilder 中 249行
1 | configuration.setCacheEnabled(booleanValueOf(props.getProperty("cacheEnabled"), true)); |
开启二级缓存后,SqlSession 就使用 CachingExecutor 对象来完成操作请求,对于查询的请求CachingExecutor 会先去二级缓存查找是否有缓存,如果有,那么直接返回给用户缓存数据,如果没有,则由 Executor 对象去完成查询操作,再把Executor 查询返回的数据存入到二级缓存中,再返回给用户。
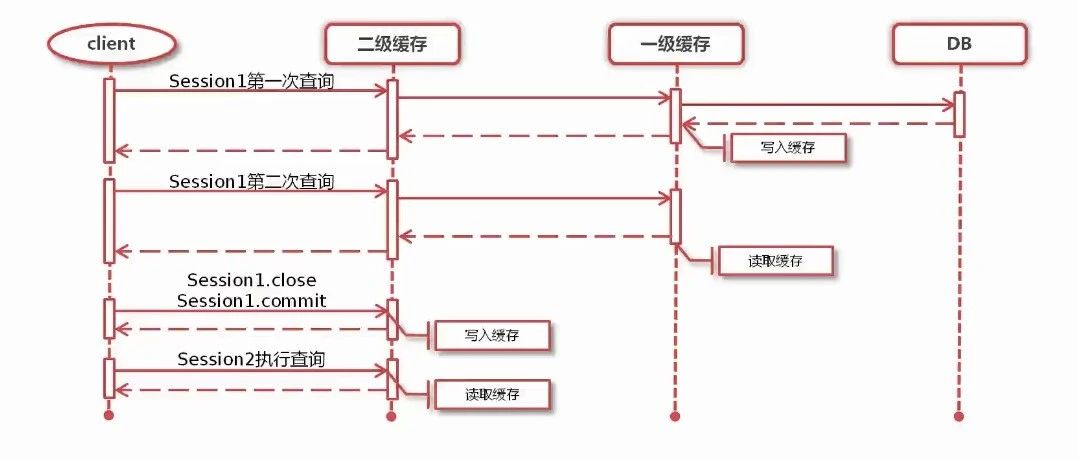
在查询一级缓存之前会先在 CachingExecutor 中查询二级缓存中是否有数据,具体查询工作流程如图:

查询的工作流程为 二级缓存 -> 一级缓存 -> 数据库
当开启二级缓存后,同一个 namespace 下的所有sql影响着同一个 Cache ,即同一个 namespace下的所有 MappedStatement 影响着同一个 Cache ,这个 Cache 被多个 SqlSession 共享,相当于一个全局变量
二级缓存的特点
MyBatis自身提供了丰富的,并且功能强大的二级缓存的实现,它拥有一系列的Cache接口装饰者,可以满足各种对缓存操作和更新的策略。在 CachingExecuter 内部有一个用来管理二级缓存的 TransactionalCacheManager 对象,TransactionalCacheManager 内部只有一个成员变量,key 是 mapper 中定义的cache对象,value 是暂时存缓存数据的对象。
TransactionalCache 装饰的对象就是定义的 cache 对象 :
1 | // key 是 `mapper` 中定义的cache对象,value 是暂时存缓存数据的对象 |
TransactionalCache 也是cache接口的装饰者之一,主要作用是保存SqlSession在事务中需要向某个二级缓存提交的缓存数据(因为事务过程中的数据可能会回滚,所以不能直接把数据就存入二级缓存,而是暂存在TransactionalCache中,在事务提交后再将过程中存放在其中的数据提交到二级缓存,如果事务回滚,则将数据清除掉)。
TransactionalCache 对象
有四个属性:
1 | // 被装饰对象 |
get
1 |
|
put
1 |
|
commit
1 | public void commit() { |
二级缓存的划分
每个 mapper 都有一个自己的 Cache 对象,也可以多个mapper共享一个 Cache 对象
- 为mapper配置一个Cache对象: 在mapper.xml中配置
<cache>节点或在接口添加@CacheNamespace注解 - 为多个mapper配置一个Cache对象: 配置
<cache-ref>节点或在接口添加@CacheNamespaceRef注解
通过 <cache-ref> 标签,定义 namespace 来指定要引用的缓存的命名空间。这句话有点绕,也就是
1 | <mapper namespace="com.ddmcc.UserMapper"> |
这时就要求 AdminUserMapper 必须定义了 <cache> 节点。如果用注解的方式如下:
1 |
|
通过以上配置,就可以让多个 Mapper 公用一个 Cache
使用二级缓存要具备的条件
Mybatis二级缓存粒度很细,可以精确到每一条查询语句是否使用缓存
在Mybatis配置中开启了缓存,并且在 mapper 中配置了 select 语句是否开启缓存 , useCache="true" 声明这条语句开启缓存后,才会使用缓存。
1 | <select id="listUser" resultType="com.ddmcc.User" useCache="true"> |
要想使用二级缓存,那么需要满足以下三个条件:
- 开启二级缓存的总开关:全局配置变量参数 cacheEnabled=true (默认开启)
- 为mapper配置了cache、cacheRef节点或者mapper接口中配置了 @CacheNamespace、@CacheNamespaceRef注解
- 该select语句节点开启了缓存useCache=”true” (默认开启)
对于我们平常使用来说,如果为一个mapper配置的cache节点,那么此mapper中的查询语句将会使用二级缓存
二级缓存的生命周期
回顾一级缓存
在 一级缓存 中,数据从数据库查询返回后,就会存入缓存中,SqlSession 执行 commit(提交),close(关闭),rollback(回滚),任何一个 update 操作或是 clearLocalCache 会清空一级缓存。
二级缓存生命周期
二级缓存则不同,上面说了在缓存创建的时候并不是直接put进缓存对象中,而是会先暂存在 TransactionalCache 对象中。当 sqlSession 关闭或提交时,再把数据刷入缓存中,如果rollback 那么不会把数据刷入缓存中,但也不会清空已有的二级缓存。sqlSession 执行任何一个 update 操作时,在事务提交后,都会去清空二级缓存。sqlSession的 clearCache 只清除自己会话中的一级缓存,并不会清除二级缓存。
但,并不是 select 语句就会存入二级缓存,update 就会清除二级缓存。主要有标签的两个参数决定:useCache和flushCache。select标签默认是 userCache=true 、flushCache=false,所以会将数据存入二级缓存。而 insert、update、delete 标签默认是 userCache=false、flushCache=true,如果将flushCache改成false,那么也不会去清除缓存
总的来说:
- sqlSession调用commit或close才会把二级缓存存入
- sqlSession执行任一update操作会清除缓存
- sqlSession回滚不会清除缓存,但本次事务内的查询数据也不会写入缓存中
- 由userCache、flushCache两个参数决定语句是否使用缓存或清除缓存
需要注意的点
数据需要sqlSession关闭或提交才会将数据写入缓存
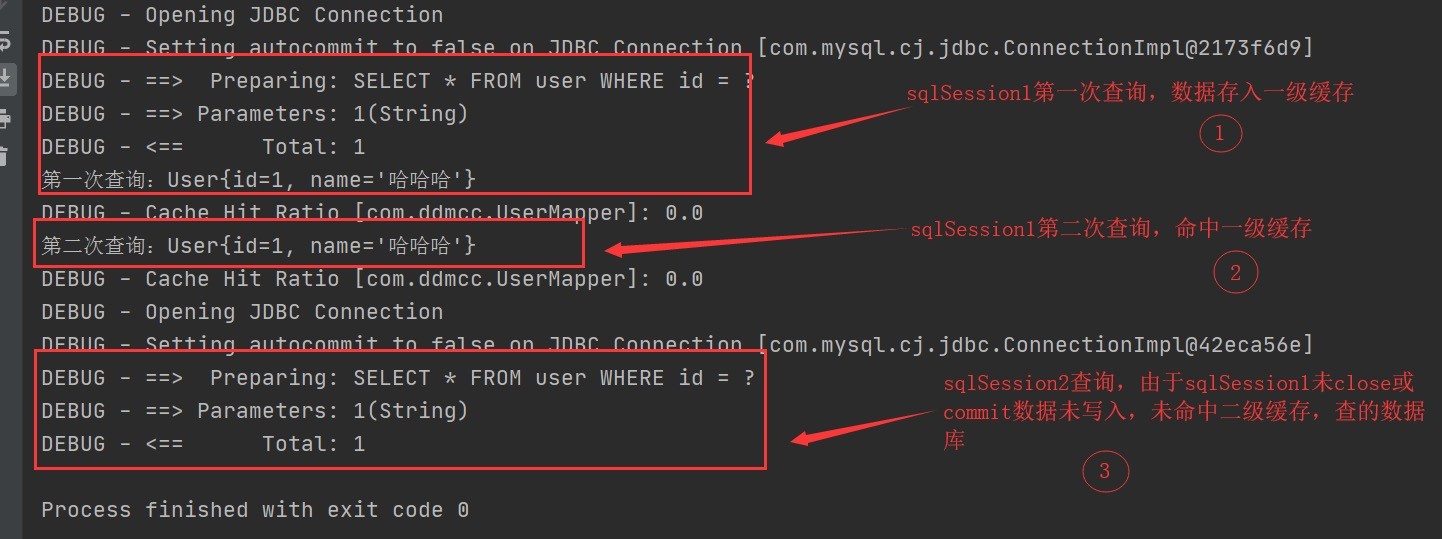
同一事务执行多次相同查询或是多个session执行同一mapper下的同一查询语句并不会命中二级缓存,因为二级缓存在 sqlSession close或commit的时候才会写入
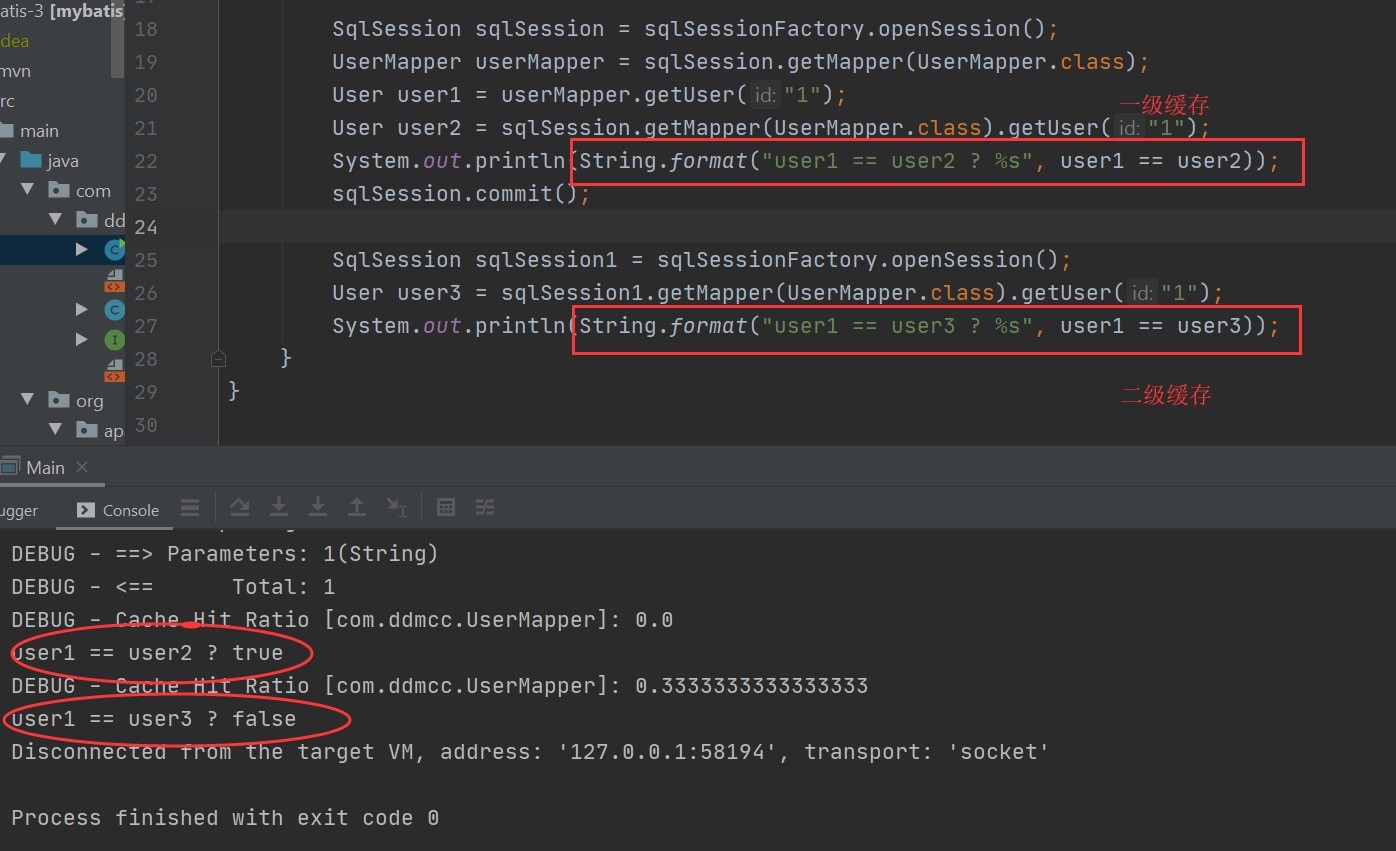
代码示例:
1 | public static void main(String[] args) throws Exception{ |
运行结果分析:
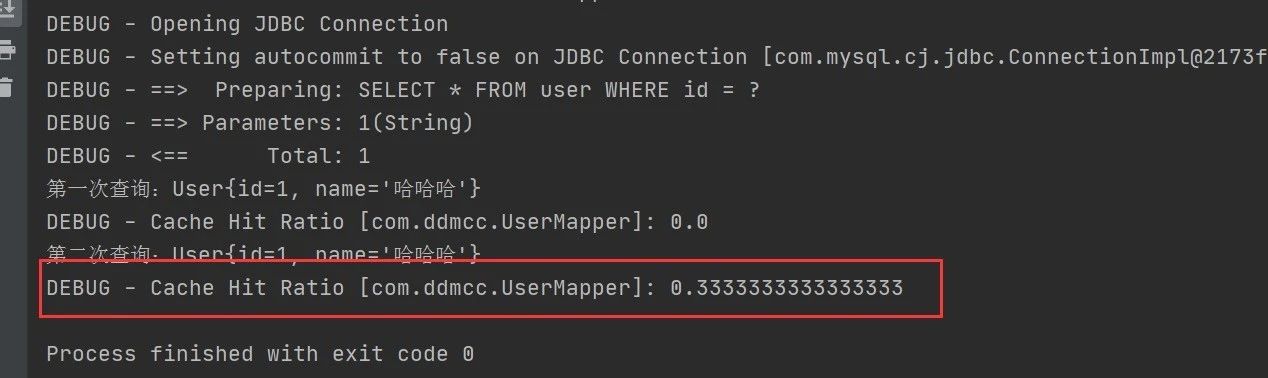
让sqlSession1提交,数据写入二级缓存
1 | ........... |
运行结果,sqlSession2命中二级缓存:
二级缓存的实体类需要实现序列化接口
cache 节点有一个 readOnly 属性,默认为false,这个属性决定缓存值是只读的还是读写的。当readOnly = false 时,Mybatis会用 SerializedCache 序列化缓存类来装饰 cache 对象,通过序列化和反序列化来保证通过缓存取出来的是一个新的对象。如果配置为只读缓存,MyBatis就会使用Map来存储缓存值(可读写缓存内部也是用PerpetualCache,在SerializedCache的put和get中进行了序列化化和反序列化),这种情况下,从缓存中获取的对象就是同一个实例。
序列化缓存
- 好处:先将对象序列化成2进制,再缓存,将对象压缩了,省内存。并且线程安全
- 坏处:是速度慢了(因为对象需要进行序列化)
Mybatis通过序列化得到对象的新实例,保证多线程安全(因为是从缓存中取数据,速度还是比从数据库获取要快)。具体说就是对象序列化后存储到缓存中,从缓存中取数据时是通过反序列化得到新的实例。
CacheBuilder类初始化缓存对象源码片段:
1 | .......... |
SerializedCache类序列化反序列化源码片段:
1 | // put |
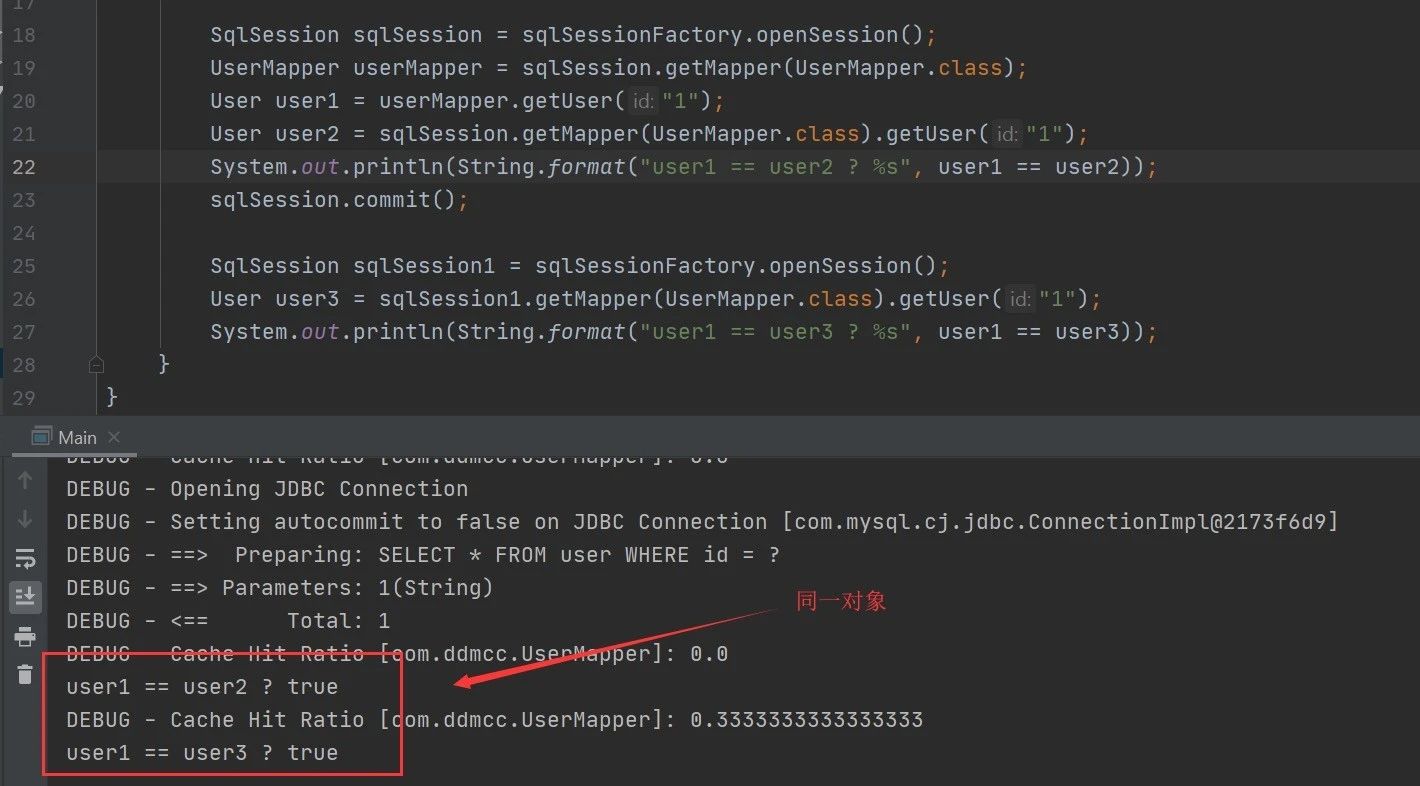
readOnly 默认为false的情况下,二级缓存取出的是一个新的对象:
将 readOnly 修改为 true,缓存取出对象为同一对象:
1 | <cache readOnly="true"/> |
Cache 节点配置属性
1 | <cache |
在默认的情况下:
映射语句文件中的所有 select 语句的结果将会被缓存。
映射语句文件中的所有 insert、update 和 delete 语句会刷新缓存。
缓存会使用最近最少使用算法(LRU, Least Recently Used)算法来清除不需要的缓存。
缓存不会定时进行刷新(也就是说,没有刷新间隔)。
缓存会保存列表或对象的1024个引用。
缓存会被视为读/写缓存,这意味着获取到的对象并不是共享的,可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改
可用的清除策略有:
LRU – 最近最少使用:移除最长时间不被使用的对象。
FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
SOFT – 软引用:基于垃圾回收器状态和软引用规则移除对象。
WEAK – 弱引用:更积极地基于垃圾收集器状态和弱引用规则移除对象。
默认的清除策略是 LRU。
flushInterval(刷新间隔)属性可以被设置为任意的正整数,设置的值应该是一个以毫秒为单位的合理时间量。 默认情况是不设置,也就是没有刷新间隔,缓存仅仅会在调用语句时刷新。
size(引用数目)属性可以被设置为任意正整数,要注意欲缓存对象的大小和运行环境中可用的内存资源。默认值是 1024。
readOnly(只读)属性可以被设置为 true 或 false。只读的缓存会给所有调用者返回缓存对象的相同实例。 因此这些对象不能被修改。这就提供了可观的性能提升。而可读写的缓存会(通过序列化)返回缓存对象的拷贝。 速度上会慢一些,但是更安全,因此默认值是 false。
提示:二级缓存是事务性的。这意味着,当 SqlSession 完成并提交时,或是完成并回滚,但没有执行 flushCache=true 的 insert/delete/update 语句时,缓存会获得更新。