扒一扒String
String不可变性
什么是不可变对象
众所周知,String 对象是不可变的。那么什么是不可变对象呢?在 Java教程 中定义:如果一个对象在构造后状态无法改变,则该对象被视为不可变。
不能改变状态的意思是,不能改变对象内的成员变量,包括基本数据类型的值不能改变,引用类型的变量不能指向其他的对象,引用类型指向的对象的状态也不能改变。
不可变对象的遵守策略(规则)
- 类中所有字段都被
final修饰,并且是私有的,也就是被private修饰。 - 不能提供修改字段或字段引用对象的
setter方法。 - 不允许子类重写方法
- 如果实例字段包含对可变对象的引用,则不允许更改这些对象:
- 不要提供修改可变对象的方法。
- 不要直接返回可变对象的引用。如有必要,可创建内部可变对象的副本,并返回可变对象的副本。
String的不可变性
定义一个字符串 s:
1 | public static void main(String[] args) { |
输出结果为:
1 | abcd |
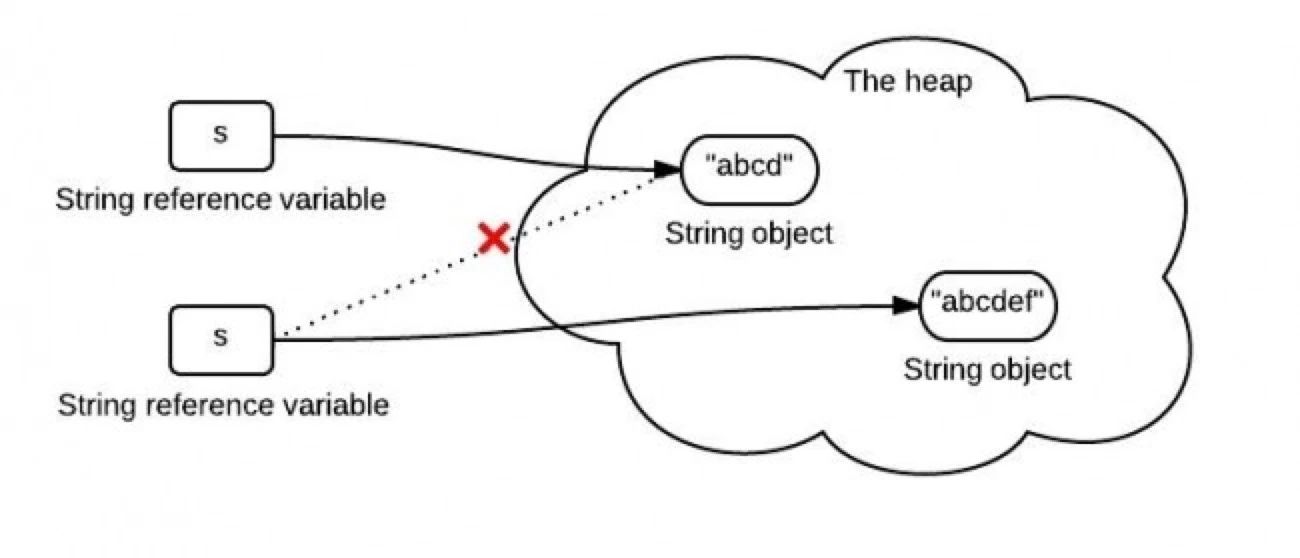
首先创建一个对象 s ,并赋值为abcd,然后再赋值为abcdef。从输出结果可以看出s的值确实改变了,那么为什么还说String对象是不可变的呢?
其实 s 变量只是保存了对象的引用,该引用指向了堆中具体的对象。如下图:
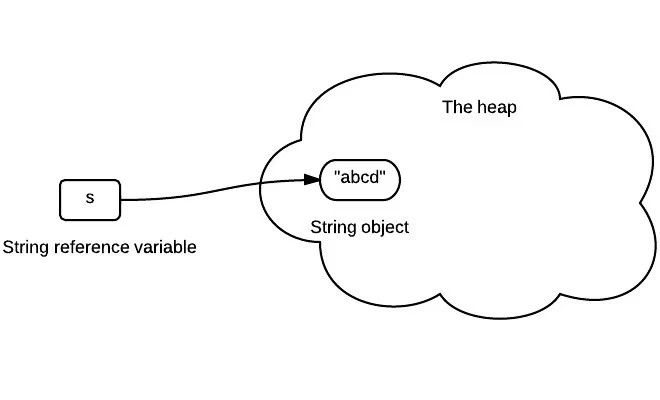
然后又创建了一个新的对象abcdef, 而引用s重新指向了这个新的对象,原来的对象abcd还在内存中存在,并没有改变。如下图:
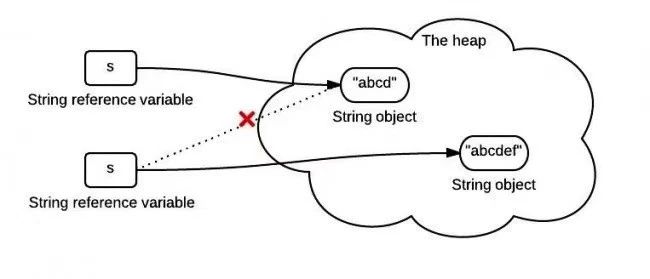
所以上面的代码仅仅改变了s的引用地址
为什么String对象是不可变的?
要理解String的不可变性,先看String类的源码:
1 | public final class String |
通过源码可以发现:String类内部是用一个字符数组来维护值的,并且被申明为 private final ,也就是value字符数组在对象被构造后就不允许重新赋值了。并且类内部也没有提供可以修改value数组值的setter方法,
所以可以认为String对象是不可变的。
可能会发现String类还提供了很多方法可以修改字符串值的方法:substring , concat , replace , replaceAll 等等。
比如 substring 方法:
1 | public static void main(String[] args) { |
执行后输出结果:
1 | abcd |
可以看到s的值确实是变了。这解释起来也很容易,看 substring 方法实现就明白了:
1 | public String substring(int beginIndex) { |
源码并不是去修改的 value 数组里的值,而是重新创建一个新的对象,并把新的对象引用赋值给s。其它修改字符串值的方法也都一样,都是创建新的对象返回。
String的值真的不可变吗?
value变量是 private final 的,也就是初始化后不可修改。它是引用变量,虽然不能重新指向其它堆内存地址,但可以通过反射去修改堆里的值。
1 | public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException { |
输出结果为:
1 | a%cd |
这个反射的实例还可以说明一个问题:如果一个对象,他组合的其他对象的状态是可以改变的,那么这个对象很可能不是不可变对象。例如一个Car对象,它组合了一个Wheel对象,虽然这个Wheel对象声明成了private final 的,但是这个Wheel对象内部的状态可以改变, 那么就不能很好的保证Car对象不可变。
JDK6与JDK7中String类实现的区别
JDK 6
String是通过字符数组实现的。在jdk 6 中,String类包含三个成员变量:char value[], int offset,int count。他们分别用来存储真正的字符数组,数组的第一个位置索引以及字符串中包含的字符个数。
下面是jdk1.6中的源码:
1 | public final class String |
当调用substring,concat等方法的时候,会创建一个新的string对象,但是这个string的值仍然指向堆中的同一个字符数组。这两个对象中只有count和offset 的值是不同的
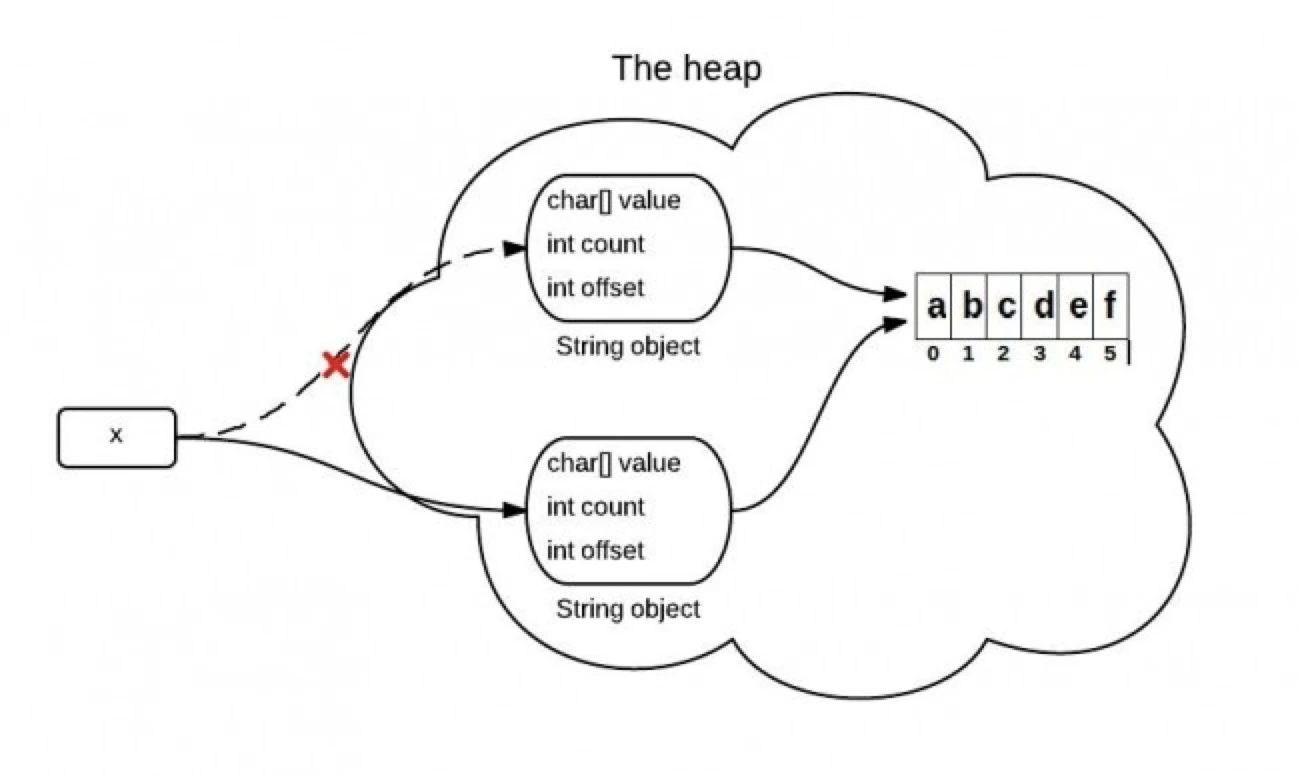
JDK 6中的substring导致的问题
如果你有一个很长很长的字符串,但是当你使用substring进行切割的时候你只需要很短的一段。这可能导致性能问题,因为你需要的只是一小段字符序列,但是你却引用了整个字符串(因为这个非常长的字符数组一直在被引用,所以无法被回收,就可能导致内存泄露)。在JDK 6中,一般用以下方式来解决该问题,原理其实就是生成一个新的字符串并引用他。
1 | x = x.substring(x, y) + "" |
内存泄露:在计算机科学中,内存泄漏指由于疏忽或错误造成程序未能释放已经不再使用的内存。 内存泄漏并非指内存在物理上的消失,而是应用程序分配某段内存后,由于设计错误,导致在释放该段内存之前就失去了对该段内存的控制,从而造成了内存的浪费。
concat也同样有该问题,如果对象a只需要很小一段字符序列,对象b去拼接了很长的字符串,这就导致如果a对象没被回收,这个很长很长的字符数组就一直不会被释放。
JDK 7
上面提到的问题,在jdk 7中得到解决。在jdk 7 中,substring,concat等方法会在堆内存中创建一个新的数组。
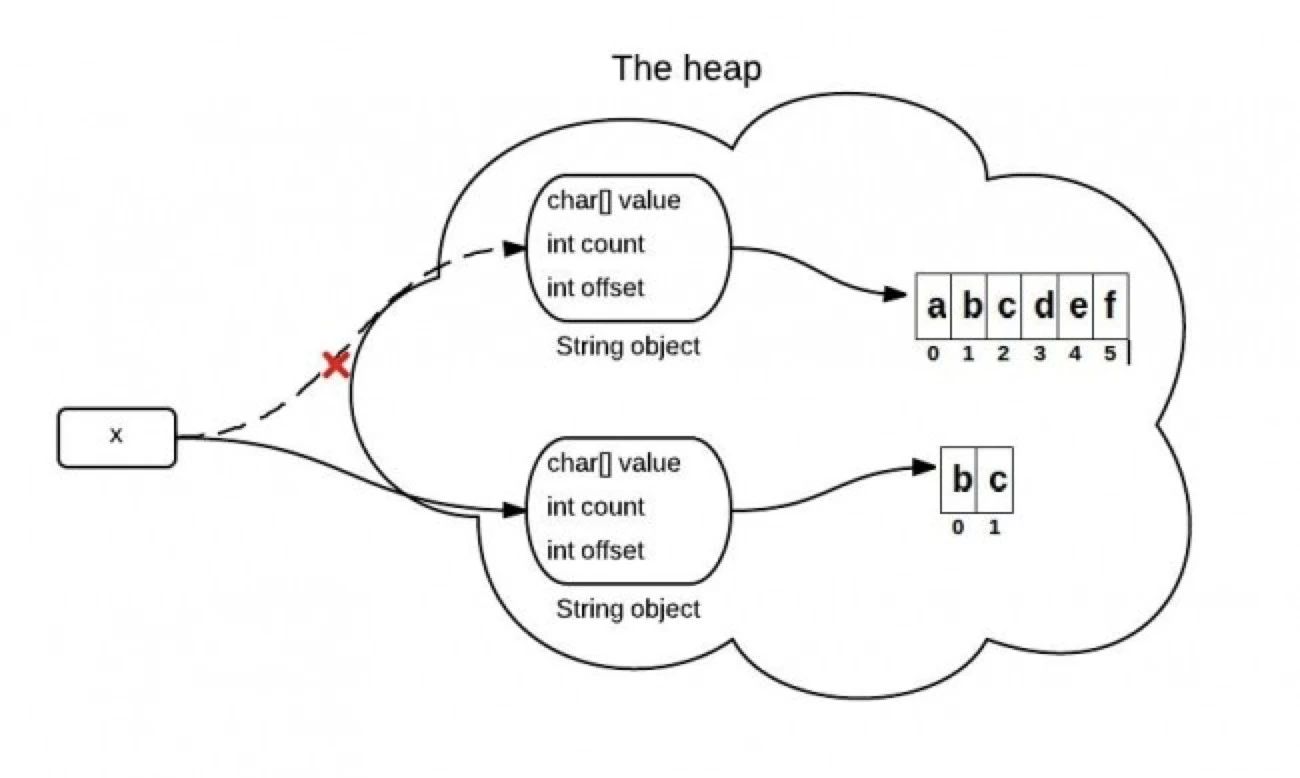
Java源码中关于这部分的主要代码如下:
1 | public String substring(int beginIndex, int endIndex) { |
以上是JDK 7中的subString方法,其使用new String创建了一个新字符串,避免对老字符串的引用。从而解决了内存泄露问题。
所以,如果你的生产环境中使用的JDK版本小于1.7,当你使用String的subString方法时一定要注意,避免内存泄露。
编译器对String字符串拼接的优化
- String s = “a” + “b”,编译器会进行常量折叠(因为两个都是编译期常量,编译期可知),即变成 String s = “ab”
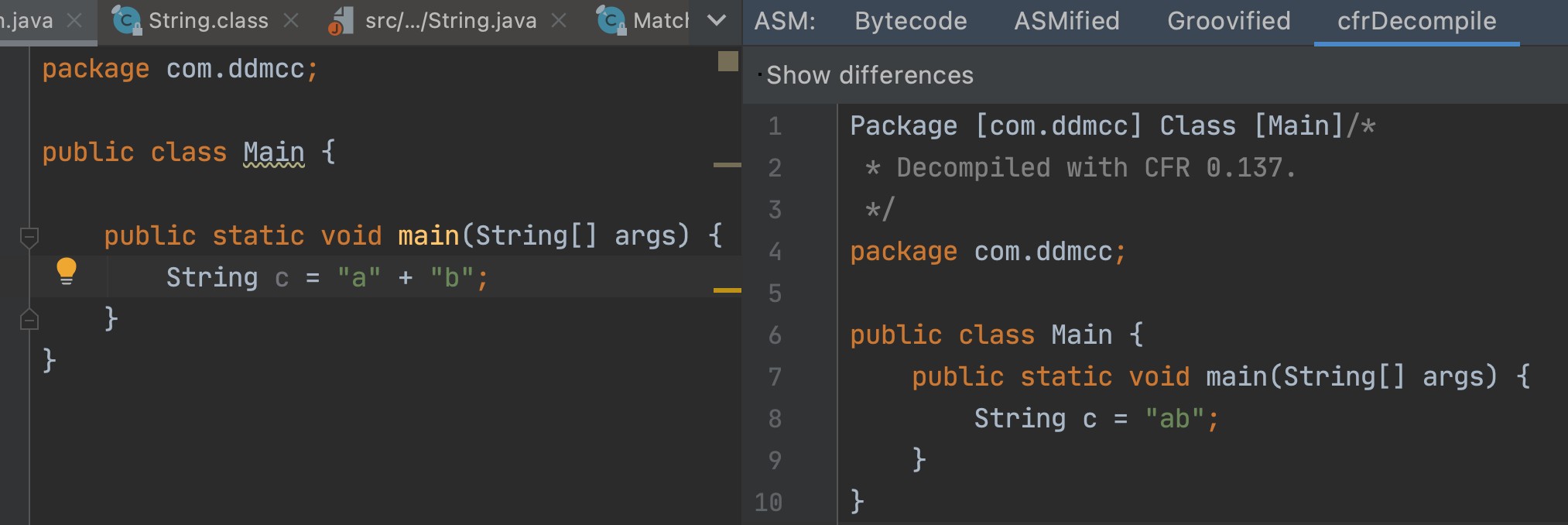
- 对于能够进行优化的(String s = “a” + var 等)用 StringBuilder 的 append() 方法替代,最后调用 toString() 方法 (底层就是一个 new String())

字符串拼接的几种方式和区别
字符串不变性与字符串拼接
其实,所有的所谓字符串拼接,都是重新生成了一个新的字符串。下面一段字符串拼接代码:
1 | String s = "abcd"; |
其实最后我们得到的s已经是一个新的字符串了。如下图
s中保存的是一个重新创建出来的String对象的引用。
1.使用 + 拼接字符串
在Java中,拼接字符串最简单的方式就是直接使用符号 + 来拼接。如:
1 | String a = "a"; |
其实使用 + 拼接字符串,只是Java提供的一个语法糖, 那么,我们就来解一解这个语法糖,看看他的内部原理到底是如何实现的。
上面代码经过反编译后如下:
1 | String a = "a"; |
通过查看反编译以后的代码,我们可以发现,原来字符串常量在拼接过程中,是将String转成了StringBuilder后,使用其append方法进行处理的。
那么也就是说,Java中的 + 对字符串的拼接,其实现原理是使用 StringBuilder.append。
2.concat
还可以使用String类中的方法concat方法来拼接字符串。如:
1 | String a = "a"; |
我们再来看一下concat方法的源代码,看一下这个方法又是如何实现的。
1 | public String concat(String str) { |
这段代码首先创建了一个字符数组,长度是已有字符串和待拼接字符串的长度之和,再把两个字符串的值复制到新的字符数组中,并使用这个字符数组创建一个新的String对象并返回。
通过源码我们也可以看到,经过concat方法,其实是new了一个新的String,这也就呼应到前面我们说的字符串的不变性问题上了。
3.StringBuffer和StringBuilder
关于字符串,Java中除了定义了一个可以用来定义 字符串常量 的 String 类以外,还提供了可以用来定义 字符串变量 的 StringBuffer和 StringBuilder 类,它的对象是可以扩充和修改的。
使用 StringBuffer 和 StringBuilder 可以方便的对字符串进行拼接。如:
1 | StringBuffer buffer = new StringBuffer("a"); |
接下来我们看看 StringBuffer和 StringBuilder 的实现原理。
和 String 类类似, StringBuffer和 StringBuilder 类也封装了一个字符数组,定义如下:
1 | char[] value; |
其append源码如下:
1 | public StringBuilder append(String str) { |
该类继承了AbstractStringBuilder类,看下其append方法:
1 | public AbstractStringBuilder append(String str) { |
append会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展。
StringBuffer 和 StringBuilder 类似,最大的区别就是 StringBuffer 是线程安全的,看一下 StringBuffer 的append方法。
1 | public synchronized StringBuffer append(String str) { |
该方法使用 synchronized 进行声明,说明是一个线程安全的方法。而 StringBuilder 则不是线程安全的。
常用的字符串拼接方式有五种,分别是使用+、使用concat、使用StringBuilder、使用StringBuffer以及使用StringUtils.join。
由于字符串拼接过程中会创建新的对象,所以如果要在一个循环体中进行字符串拼接,就要考虑内存问题和效率问题。
因此,经过对比,我们发现,直接使用StringBuilder的方式是效率最高的。因为StringBuilder天生就是设计来定义可变字符串和字符串的变化操作的。
但是,还要强调的是:
1、如果不是在循环体中进行字符串拼接的话,直接使用+就好了。
2、如果在并发场景中进行字符串拼接的话,要使用StringBuffer来代替StringBuilder。
switch对String的支持
Java 7中,switch的参数可以是String类型了。到目前为止switch支持这样几种数据类型:byte short int char String
还是先上代码:
1 | public static void main(String[] args) { |
对代码进行反编译:
1 | public static void main(String args[]) |
看到这个代码,你知道原来字符串的switch是通过equals()和hashCode()方法来实现的。记住,switch中只能使用整型,比如byte。short,char(ackii码是整型)以及int。还好hashCode()方法返回的是int,而不是long。通过这个很容易记住hashCode返回的是int这个事实。仔细看下可以发现,进行switch的实际是哈希值,然后通过使用equals方法比较进行安全检查,这个检查是必要的,因为哈希可能会发生碰撞。因此它的性能是不如使用枚举进行switch或者使用纯整数常量,但这也不是很差。因为Java编译器只增加了一个equals方法,如果你比较的是字符串字面量的话会非常快,比如”abc” ==”abc”。如果你把hashCode()方法的调用也考虑进来了,那么还会再多一次的调用开销,因为字符串一旦创建了,它就会把哈希值缓存起来。因此如果这个switch语句是用在一个循环里的,比如逐项处理某个值,或者游戏引擎循环地渲染屏幕,这里hashCode()方法的调用开销其实不会很大。