InnoDB存储引擎中的锁
我们都知道事务的4个特性,即 ACID。mysql 数据库使用加锁的方式来实现其中的 I (Isolation隔离性)。对于 InnoDB 存储引擎来说,它 支持行锁和表锁 ,而且行锁是由存储引擎通过给索引记录加锁来实现的,并且 InnoDB 默认是加行锁。好处就是锁定颗粒度小,发生锁冲突的概率低,并发度高
InnoDB存储引擎中的锁
我们都知道事务的4个特性,即 ACID。mysql 数据库使用加锁的方式来实现其中的 I (Isolation隔离性)。对于 InnoDB 存储引擎来说,它 支持行锁和表锁 ,而且行锁是由存储引擎通过给索引记录加锁来实现的,并且 InnoDB 默认是加行锁。好处就是锁定颗粒度小,发生锁冲突的概率低,并发度高
锁的类型
InnoDB 实现了两种行级锁:
- 共享锁(S) : 允许事务读一行数据
- 排他锁(X):允许事务删除或更新一行数据
其中,X 锁与任何的锁都不兼容,而 S 锁仅和 S 锁兼容。即如果一个事务已经获得了行的 S锁,那么另外的事务可以立即获得这行的 S 锁,因为读取并没有改变行的数据,称这种情况为锁兼容。 但若有其他的事务想获得行的 X 锁,则其必须等待事务释放行上的 S 锁

InnoDB 存储引擎除了行锁以外,还有表锁,通常也称为意向锁,其设计目的主要是为了指示事务稍后对表中的行需要哪种类型的锁(共享或独占)。其支持两种意向锁:
- 意向共享锁(IS Lock),事务想要获得一张表中某几行的共享锁
- 意向排他锁(IX Lock),事务想要获得一张表中某几行的排他锁
如果需要对页上的记录 r 进行上 X 锁,那么分别需要对数据库、表、页上 IX,最后对记录 r 上 X 锁。若中间有任何一个部分导致等待,那么该操作需要等待粗粒度锁释放。 举例来说,在对记录 r 加 X 锁之前,已经有事务对表进行了 S 表锁,那么表上已存在 S 锁,之后事务需要对记录 r 在表上加上 IX,由于不兼容,所以该事务需要等待表锁操作的完成
InnoDB 存储引擎中锁的兼容性:

设计意向锁的目的何在?
假设事务1,用 X 锁来锁住了页上的几条记录,那么此时表、页上存在 IX 锁,即意向排他锁。此时事务2要进行LOCK TABLE … WRITE的表级别锁的请求或者事务2进行 DML 操作且未使用索引而升级为表锁时,可以直接根据意向锁是否存在而判断是否有锁冲突。如果没有这个意向锁,那么可能需要遍历整个表记录才能知道表是不是有记录被锁
DML表锁与MDL表锁
mysql 里面表级别的锁有两种:一种是表锁,一种是元数据锁(metadata lock,MDL)
表锁
表锁的语法是 lock tables … read/write。可以用 unlock tables 主动释放锁,也可以在客户端断开的时候自动释放,commit 和 rollback 并不会释放锁(准确的说是InnoDB释放了内部表锁,server没释放表锁)
需要注意,lock tables 语法除了会限制别的线程的读写外,也限定了本线程接下来的写。举个例子,如果在某个线程 A 中执行 lock tables t1 read, t2 write; 这个语句,则其他线程写 t1、读写 t2 的语句都会被阻塞。同时,线程 A 在执行 unlock tables 之前,也只能执行读 t1、读写 t2 的操作。写 t1 并不允许,也不能读写其他表
MDL元数据锁(metadata lock)
MDL 不需要显式使用,在访问一个表的时候会被自动加上。在 MySQL 5.5 版本中引入了 MDL,当对一个表做增删改查操作的时候,加 MDL 读锁;当要对表做结构变更操作的时候,加 MDL 写锁
- MDL 读锁之间不互斥,因此你可以有多个线程同时对一张表增删改查
- 读写锁之间、写锁之间是互斥的,用来保证变更表结构操作的安全性。因此,如果有两个线程要同时给一个表加字段,其中一个要等另一个执行完才能开始执行
外键和锁
自增长与锁
锁的算法
InnoDB 通过给索引项加锁来实现行锁,如果没有索引,则通过隐藏的聚簇索引来对记录加锁。如果操作不通过索引条件检索数据,InnoDB 则对表中的所有记录加锁,实际效果就和表锁一样
InnoDB 存储引擎有3种行锁的算法,分别是:
- Record Lock: 单个记录上的锁
- Gap Lock: 间隙锁,锁定一个范围,但不包括本记录
- Next-Key Lock: Gap Lock+Record Lock,锁定一个范围,并且锁定记录本身
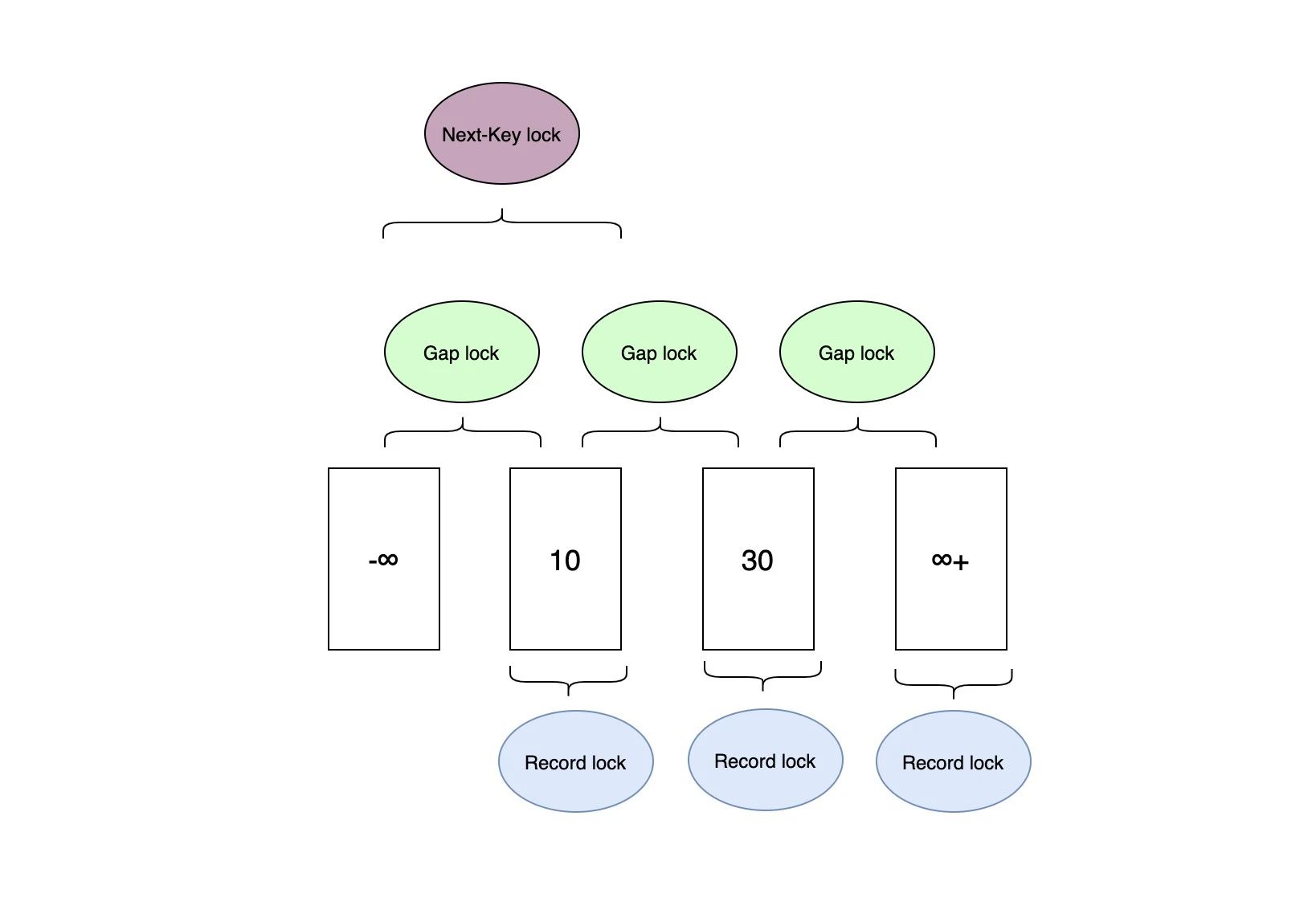
例如一个索引有10,30这两个值,InnoDB 可以根据需要使用 Record Lock 将10,30两个索引锁住;也可以使用 Gap Lock 将(-∞,10),(10,30),(30, +∞)三个范围区间锁住;Next-Key Lock 类似于上述两种锁的结合,它可以锁住的区间有为(-∞,10],(10,30],(30, +∞),可以看出它即锁定了一个范围,也会锁定记录本身
InnoDB 对于行的查询都是默认采用 Next-Key lock 算法。当条件索引是唯一索引时,InnoDB 存储引擎会进行优化,将其降级为 Record Lock,即锁住索引本身 ,而不是范围,从而提高并发性。若是通过辅助索引查询,不但会给辅助索引加锁,还会为聚集索引上锁。对于辅助索引加 Next-Key Lock,而聚集索引因为是唯一的,所以只会加 Record Lock
对于没有显示创建索引的表,则会对 rowId 的聚集索引来加锁。如果操作未使用索引查询,那么会对表中所有记录加锁,实际效果和表锁一样
参考
《MySQL技术内幕InnoDB存储引擎第2版》